174region174
Active member
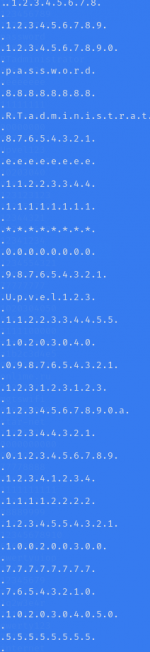
My dictionaries have the form
What command should I run to get the file of this form?
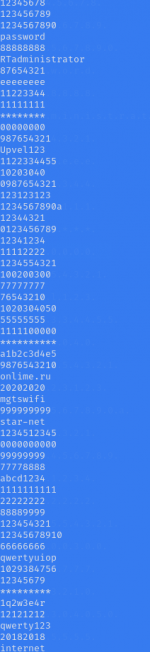
I noticed. The dictionary in Figure 2 contains more words. It takes up less hard disk space.
What command should I run to get the file of this form?
I noticed. The dictionary in Figure 2 contains more words. It takes up less hard disk space.
Attachments
-
 dic1.png13.4 KB · Views: 79
dic1.png13.4 KB · Views: 79 -
 dic2.png112 KB · Views: 80
dic2.png112 KB · Views: 80